Section II. MODELING¶
Chapter 3. Coordinates and Transformations¶
In almost all fields of science and engineering, it is essential to identify and manipulate mathematical representations of physical, real-world quantities. Robotics is no exception. Intelligent robots build a "mental model" of themselves and the world as they perceive their environments, and they modify those models when interpreting the past and predicting the future. In an abstract sense, these models are simply a collection of numbers and labels, with no explicit meaning to the robot. It is the job of a robot engineer to correctly associate numbers with meaning, and correspondingly, meanings with numbers. (If this sounds like mumbo jumbo at the moment, some concrete examples will be offered soon enough!)
Two of the most important mathematical representations are vectors and matrices from linear algebra. Vectors are often representations of positions or directions in two or three dimensions of space, but can also represent other quantities like sensor measurements. Matrices are representations of how representations change, either through an action, or even through a change in how those numbers are interpreted. We will be using them liberally throughout the book, and they appear in almost every subject of robotics. Hence, they must be mastered to get anywhere beyond a superficial understanding of the material.
This chapter discusses how vectors and matrices are used in robotics to represent 2D and 3D positions, directions, rigid body motion, and coordinate transformations. It is assumed that all students will have taken a course in linear algebra and can refresh themselves on basic definitions. Appendix 1 reviews the standard vector and matrix notation, conventions, and basic identities that will be used throughout this book.
Vectors and coordinates¶
Vectors extend concepts that are familiar to us from working with real numbers $\mathbb{R}$ to other spaces of interest. They also succinctly represent collections of real numbers that have a common meaning like position or direction, or readings from a signal taken at a given time. They make mathematical expressions more compact, which helps us wrap our heads around more difficult concepts.
Most often, $n$-dimensional Euclidean spaces $\mathbb{R}^n$ is used, in which a vector is simply a tuple of $n$ real numbers. The "list of numbers" interpretation is the most common way that vectors are conceived of by engineers and computer scientists, and that is certainly how they are stored and operated upon. Let us call this the "layman's definition" of vectors. However, it is often important to realize that these numbers are just an interpretation of a more abstract essential concept -- the underlying physical meaning -- and the numbers will change depending on their manner of interpretation, such as a chosen frame of reference. This section will present common operations in 2D and 3D, and follow it with a discussion about the importance of separating meaning from representation.
2D coordinate frames¶
In the "layman's definition", an $n$-dimensional vector $\mathbf{x}$ is a tuple of real numbers $\mathbf{x}=(x_1,\ldots,x_n) \in \mathbb{R}^n$. For now, we will work in $\mathbb{R}^2$. We will use boldface notation only temporarily to help distinguish between vectors and real numbers. In the future, the boldface will typically be dropped.
A 2D position $P$ is represented by a 2-element vector $\mathbf{p}=(p_x,p_y)$ that gives its coordinates relative to axis directions $X$ and $Y$, offset from a position $O$ where the axes cross, called the origin (Fig. 1). We will also represent vectors in column vector form:
for use in matrix-vector products. Both parenthetical and column vector notations are equivalent and interchangeable.

The items $O$, $X$, and $Y$ define the coordinate frame in which the coordinates are interpreted. Here $O$ is an arbitrary position in space, and $X$ and $Y$ are orthogonal directions with $Y$ rotated $90^\circ$ counter-clockwise from $X$. Note that in isolation, a vector of coordinates does not define a position. A physical position is only defined by coordinates in reference to a certain coordinate frame. The frame will often be left implicit, or spoken of as the reference frame of the coordinates.
3D coordinate frames¶
The situation in 3D space is similar, except that we represent a 3D position $P$ with a 3-element vector $\mathbf{p}=(p_x, p_y, p_z)$ that gives its coordinates relative to axes $X$, $Y$, and $Z$ and offset from an origin $O$ in 3D space where the axes cross. The parenthetical notation is equivalent to the column vector form:
$$ \mathbf{p} = \begin{bmatrix} p_x \\ p_y \\ p_z \end{bmatrix}. $$In 3D the coordinate frame consists of the origin $O$ and the mutually orthogonal axes $X$, $Y$, and $Z$. In this book we will use right-handed coordinate convention in which the axes can be envisioned in the layout of the first three fingers of the right hand, suitably arranged at $90^\circ$ right angles. $X$ axis corresponds to the thumb, $Y$ axis corresponds to the index finger, and $Z$ axis corresponds to the middle finger.
Directional quantities¶
Vectors are also used to represent directional quantities, such as a displacement, direction, or derivative. A displacement is a difference between points, e.g., $\mathbf{q}-\mathbf{p}$ gives the amount that would need to be moved in both the $X$ and $Y$ direction to move from $P$ to $Q$, where $\mathbf{q}$ gives the coordinates of $Q$ relative to the same reference frame. It has both a direction and a magnitude. In contrast, a direction does not have magnitude, and is a unit vector. The direction from $P$ to $Q$ is given by
$$ \frac{\mathbf{q}-\mathbf{p}}{\|\mathbf{q}-\mathbf{p}\|}. $$In 2D, a direction can also be given as an angle $\theta \in [0,2\pi)$ rad, with the convention that the angle measures the counter-clockwise direction from the $X$ axis. The corresponding unit vector is $(\cos(\theta),\sin(\theta))$.

A derivative is an infinitesimal displacement. If the position $P(t)$ is a function of $t$, then its derivative $\mathbf{p}^\prime(t)$ is a vector $(p_x(t),p_y(t))$.
The major difference between directional and position quantities is that coordinates of directional quantities do not vary with respect to the choice of origin. However, coordinates of both positions and directions are affected by the choice of coordinate axes.
Geometric operations¶
The coordinates of a point $\mathbf{p}$ after translation by a displacement $\mathbf{d}$ can be computed by vector addition $\mathbf{p} + \mathbf{d}$. Interpolation and extrapolation between points $\mathbf{p}$, $\mathbf{q}$ is specified by the equation
$$ \mathbf{x}(u) = (1-u)\mathbf{p} + u\mathbf{q} $$for $u \in \mathbb{R}$. This equation starts at $\mathbf{x}(0) = \mathbf{p}$ at $u=0$, and ends at $\mathbf{x}(1)=\mathbf{q}$ at $u=1$. Extrapolation can be obtained with $u < 0$ or $u > 1$, as shown in Figure 4.a.
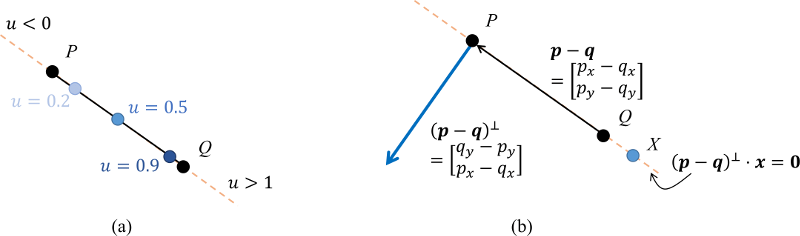
The line through $\mathbf{p}$ and $\mathbf{q}$ can be obtained by sweeping the above interpolation / extrapolation formula across the entire range of $u \in \mathbb{R}$. The line segment between $\mathbf{p}$ and $\mathbf{q}$ is obtained by sweeping $u$ across the range $[0,1]$.
An other useful definition of a line in 2D uses a point on the line and an orthogonal direction. We define $\mathbf{p}^\perp = (-p_y,p_x)$ as an orthogonal direction to $\mathbf{p}=(p_x,p_y)$, which has the same magnitude but is rotated 90$^\circ$ clockwise. The line through the origin passing through $\mathbf{p}$ can be expressed in the form of all solutions $\mathbf{x}$ to the equation $\mathbf{x} \cdot \mathbf{p}^\perp = 0$. Similarly, the line through points $P$ and $Q$ can be expressed as the equation
$$ \mathbf{x} \cdot (\mathbf{p} - \mathbf{q})^\perp = \mathbf{p} \cdot (\mathbf{p} - \mathbf{q})^\perp $$Another expression of lines is the following:
$$ \mathbf{x} \cdot \mathbf{n} = c $$Where $\mathbf{n}$ is orthogonal to the direction of the line and $c = \mathbf{p} \cdot \mathbf{n}$ for any point $\mathbf{p}$ on the line. (Fig. 4.b.)
This definition is known as the plane equation, which generalizes lines in 2D to planes in 3D and hyperplanes in higher dimensions. Each of these is object of $n-1$ dimensions in an $n$-dimensional space, which we call a generalized plane. A unique representation for a generalized plane is $\mathbf{x}\cdot \mathbf{u} = b$ where $\mathbf{u}$ is a unit vector orthogonal to the plane known as the normal direction and $b$ is a nonnegative offset that determines the distance away from the origin.
Transformations¶
Transformations are functions that map $n$-D vectors to other $n$-D vectors: $T : \mathbb{R}^n \rightarrow \mathbb{R}^n$. They can represent geometric operations, which are caused by movement or action, as well as changes of coordinates, which are caused by changes of interpretation. Many common spatial transformations, including translations, rotations, and scaling are represented by matrix / vector operations. Changes of coordinate frames are also matrix / vector operations. As a result, transformation matrices are stored and operated on ubiquitously in robotics.
Linear transformations¶
A linear transformation is one that can be represented as a matrix operation
$$\mathbf{y} = A\mathbf{x}$$where $\mathbf{x} \in \mathbb{R}^m$, $\mathbf{y} \in \mathbb{R}^n$, and A is an $m \times n$ matrix. In particular, in 2D, this operation takes the form
$$ \begin{bmatrix}q_x \\ q_y \end{bmatrix} = \begin{bmatrix} a & b \\ c & d \end{bmatrix} \begin{bmatrix}p_x \\ p_y \end{bmatrix} = \begin{bmatrix} a p_x + b p_y\\ c p_x + d p_y \end{bmatrix}. $$In 3D, a linear transformation takes the form
Rotations in 2D¶
Rotations about the origin by angle $\theta$ can be defined as linear transformations. Consider two reference frames with a common origin $O$, the pre-rotation axes $X$ and $Y$, and the post-rotation axes $X^\prime$ and $Y^\prime$. Depicting $X^\prime$ on top of $X$ and $Y$ as a line emanating from the origin, and using a little trigonometry, we shall see that $X^\prime$ has coordinates $\mathbf{x}^\prime = (\cos \theta,\sin \theta)$. It is a bit more involved, but not much, to determine that $Y^\prime$ has coordinates $\mathbf{y}^\prime = (-\sin \theta, \cos \theta)$.
Now consider that along with the coordinate frames, a point $P$ was rotated to $P^\prime$. We will derive how to determine its new coordinates relative to the original reference frame. Notice that $P^\prime$ still has coordinates $(p_x,p_y)$ relative to the post-rotation frame $X^\prime$, $Y^\prime$, since distances do not shrink or grow when objects are rotated. Specifically, $P^\prime$ is obtained by walking $p_x$ units from the origin in the direction of $X^\prime$, and then $p_y$ units in the direction of $Y^\prime$ (Fig. 5). Hence, to determine its coordinates in the original reference frame, we can use the fact that the coordinates of $X^\prime$ and $Y^\prime$ are known:
$$ \mathbf{p}^\prime = p_x \mathbf{x}^\prime + p_y \mathbf{y}^\prime = \begin{bmatrix} p_x \cos \theta - p_y \sin \theta \\ p_x \sin \theta + p_y \cos \theta \end{bmatrix}. $$

A more compact and convenient way of writing this is with a matrix equation $$\mathbf{p}^\prime = R(\theta) \mathbf{p}$$ with the rotation matrix given by
$$ R(\theta) = \begin{bmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{bmatrix}. $$There are several useful properties of such matrices:
The matrix composition $R(\theta_1) R(\theta_2) = R(\theta_1 + \theta_2)$ gives the rotation matrix for the sum of the angles.
The determinant $\det(R(\theta)) = \cos^2 \theta + \sin^2 \theta = 1$ for all $\theta$.
Due to the identities $\cos(-\theta) = \cos(\theta)$ and $\sin(-\theta) = - \sin(\theta)$, the operation of rotating about $-\theta$ is equivalent to a matrix transpose:
$$ R(-\theta) = \begin{bmatrix} \cos \theta & \sin \theta \\ -\sin \theta & \cos \theta \end{bmatrix} = R(\theta)^T. $$
Moreover, the transpose is equivalent to the matrix inverse:
$$R(-\theta) = R(\theta)^T = R(\theta)^{-1}.$$
In other words, rotation matrices are orthogonal.
Vector norms are invariant under rotation:
$$\| R(\theta) \mathbf{x} \| = \| \mathbf{x} \|.$$
The rotation matrix is only dependent on the argument's value modulo $2\pi$.
The space of rotations is known as the special orthogonal group $SO(2)$. The reason why it is called the special orthogonal group is that it is the set of all orthogonal $2\times 2$ matrices with positive determinant, while there do exist other orthogonal matrices with determinant -1.
Property 4 implies that it is more proper to consider rotation matrices as only representing instantaneous orientation rather than accumulated amounts of revolution. For example, if a motor has spun $720^\circ$, the matrix representation is indistinguishable from the 0 rotation. In certain applications that demand reasoning about accumulated revolution, the representation $\theta \in \mathbb{R}$ is more appropriate than a matrix. More about this topic will be discussed when we cover topological spaces.
Rotations in 3D¶
In 3D, rotations can also be defined as linear transformations, although parameterizing them is not as simple as in 2D. In the next chapter, 3D rotation representations will discussed in further detail, but for now let us describe some of their properties.
A rotation in 3D can be represented by a matrix equation $$\mathbf{p}^\prime = R \mathbf{p}$$ with $R$ a $3\times 3$ rotation matrix.

Like in 2D, rotation matrices satisfy several properties:
The composition of two rotation matrices $R_1 R_2$ is also a rotation matrix.
In general, however, $R_1 R_2 \neq R_2 R_1$ unless the two are rotations about a shared axis.
The determinant $\det(R) = 1$ for all rotation matrices.
The transpose of a rotation matrix is its inverse: $R^T = R^{-1}$, or $R R^T = R^T R = I$.
Vector norms are invariant under rotation.
The space of 3D rotations is known as the special orthogonal group $SO(3)$.
Another interpretation of rotation matrices is to interpret each of the 3 columns as the coordinates of each of the coordinate axes after rotation. In other words, when a coordinate frame rotates by matrix $R$ about the origin, the entries of the rotation matrix can be interpreted as:
$$ R = \begin{bmatrix} x_x & y_x & z_x \\ x_y & y_y & z_y \\ x_z & y_z & z_z \end{bmatrix} $$where $(x_x,x_y,x_z)$ give the coordinates of the new $X$ axis in the old frame, $(y_x,y_y,y_z)$ gives the coordinates of the new $Y$ axis, and $(z_x,z_y,z_z)$ gives the coordinates of the new $Z$ axis.

This interpretation is useful when determining the coordinates of a rotated point in the original reference frame: if the point is given by coordinates $\mathbf{p} = (p_x,p_y,p_z)$ such that $P-O = p_x X + p_y Y + p_z Z$, then the new coordinates of $P$ relative to the old reference frame are given by $R \mathbf{p}$.
Scaling¶
Axis-aligned scaling in 2D about the origin can be represented as a linear transform with matrix
$$ S(s_x,s_y) = \begin{bmatrix}s_x & 0 \\ 0 & s_y \end{bmatrix} $$where $s_x$ is the scaling about the $X$ direction and $s_y$ is the scaling about the $Y$ direction. If $s_x = s_y$ this is known as a uniform scaling.
This definition can be generalized to $n$-D space using an $n$-D scaling vector $\mathbf{s}$ which determines the scaling in each direction by mapping to the diagonal of an $n \times n$ matrix:
$$ S(\mathbf{s}) = diag(\mathbf{s}). $$Compositions of linear transformations¶
When performing two linear transformations one after another, the results are determined via matrix multiplication. Suppose that $T_1(\mathbf{x})$ and $T_2(\mathbf{x})$ are both linear transformations with matrices $A$ and $B$, respectively. When performing the operation of $T_2$ first to obtain $\mathbf{y} = T_2(\mathbf{x})$, then performing $T_1$ to obtain $\mathbf{z}=T_1(\mathbf{y})$, the ultimate result is:
$$ \mathbf{z} = T_1(T_2(\mathbf{x})) $$where it should be noted that $T_1$ appears first in the equation even though it is performed after $T_2$. Expanding this into matrix products,
$$ \mathbf{z} = A B \mathbf{x} $$holding for all values of $\mathbf{x}$. As a result, the function composition $T_1 \circ T_2$ is also a linear transformation with matrix $AB$.
Using composition we can derive other useful transformations, like scaling not aligned to an axis. Suppose we wish to scale some coordinates by value $s$ in a direction $\mathbf{v}$, where $\mathbf{v}$ is a unit vector. We can think of this as first rotating by an angle $\theta$ so that the $X$ axis is aligned with $\mathbf{v}$, then performing an axis-aligned scaling, then rotating back to the original coordinate frame:
$$ A = R(-\theta) S(s,1) R(\theta). $$It so happens that
$$ R(\theta) = \begin{bmatrix}v_x & v_y \\ -v_y & v_x \end{bmatrix} $$performs the rotation that we desire. As a result we can compute:
$$ \begin{aligned} A & = \begin{bmatrix}v_x & -v_y \\ v_y & v_x \end{bmatrix} \begin{bmatrix}s & 0 \\ 0 & 1 \end{bmatrix} \begin{bmatrix}v_x & v_y \\ -v_y & v_x \end{bmatrix} = \begin{bmatrix}v_x & -v_y \\ v_y & v_x \end{bmatrix} \begin{bmatrix}sv_x & sv_y \\ -v_y & v_x \end{bmatrix} \\ & = \begin{bmatrix}s v_x^2 + v_y^2 & s v_x v_y - v_y v_x \\ s v_x v_y - v_x v_y & s v_y^2 + v_x^2 \end{bmatrix} = I + (s-1)\begin{bmatrix}v_x^2 & v_x v_y \\ v_x v_y & v_y^2\end{bmatrix}\end{aligned} $$Note that due to the non-symmetricity of matrix multiplication, order of transformation matters: a rotation followed by a scaling is not necessarily the same as a scaling followed by a rotation. However, with a little inspection, we can derive the following symmetric compositions:
As a consequence of $R(\theta_1) R(\theta_2) = R(\theta_1 + \theta_2)$, rotation by angle $\theta_1$ followed by angle $\theta_2$ is symmetric: $R(\theta_1) R(\theta_2) = R(\theta_2) R(\theta_1)$. (Note that symmetry does not generally hold in 3D!)
A rotation and a uniform scaling.
Two axis-aligned scalings.
Rigid transformations¶
Rigid transformations in two dimensions have two properties:
The distance between two points do not change after being transformed.
In 2D, the orientation and area of any triangle does not change, and in 3D, the orientation and volume of any tetrahedron does not change.
The form of all rigid transforms is a rotation $R$ followed by an arbitrary translation $\mathbf{t}$:
$$ T(\mathbf{x}) = R \mathbf{x} + \mathbf{t} $$Which can be thought of applying a rotation about the origin first, and then a translation second. Proving that all rigid transforms have this form will be left as an exercise.
It is also possible to interpret rigid transforms as rotation about an arbitrary point. Letting the center of rotation be denoted $\mathbf{c}$, a rotation about $\mathbf{c}$ can be constructed by translating a point so that $\mathbf{c}$ is the origin, then rotating about the origin by some matrix $R$, and then translating back to the original origin. This form is: $$T(\mathbf{x}) = R(\mathbf{x} - \mathbf{c}) + \mathbf{c}.$$ The parenthetical term is the translation to $\mathbf{c}$ as the origin, the multiplication by $R$ is the rotation about the new origin, and the addition of $\mathbf{c}$ is the translation back to the original origin. These two representations are related by $\mathbf{t} = \mathbf{c} - R\mathbf{c}$, and $\mathbf{c} = (I - R)^{-1} \mathbf{t}$.
The set of rigid transformations is called the special Euclidean group $SE(2)$ in 2D, and $SE(3)$ in 3D. Repeated application of rigid transformations also produce a rigid transformation. Given two rigid transforms
$$ T_1(\mathbf{x}) = R_1\mathbf{x} + \mathbf{t_1} $$and
$$ T_2(\mathbf{x}) = R_2\mathbf{x} + \mathbf{t_2} $$then the composite transform $T_1 \circ T_2$ is the operation of performing $T_2$ first, then $T_1$. If we let $\mathbf{y} = T_2(\mathbf{x})$, and $\mathbf{z} = T_1(\mathbf{y})$, then we obtain:
$$ \mathbf{z} = T_1(T_2(\mathbf{x})) = R_1 (R_2\mathbf{x} + \mathbf{t_2}) + \mathbf{t_1}. $$By the distributive property of matrix multiplication, we have
$$ \mathbf{z} = R_1 R_2\mathbf{x} + R_1 \mathbf{t_2} + \mathbf{t_1}. $$This is simply a rigid transform with rotation matrix $R_1 R_2$ and translation by $(R_1 \mathbf{t_2} + \mathbf{t_1})$.
Inverse transformations¶
Not all transformations have inverses, but rotations, translations, rigid transformations, and many linear transformations do. As described before, the inverse of a rotation matrix is simply its transpose. Translations are inverted by translating in the negative direction. Linear transforms $A\mathbf{x}$ are invertible only if the matrix is invertible, with the inverse transformation $A^{-1}\mathbf{x}$.
Rigid transformations are also invertible, and their inverse is also a rigid transformation: $$\label{eq:RigidTransformInverse} T_{(R,\mathbf{t})} ^{-1} = T_{(R^{T},-R^{T} \mathbf{t})}$$ where $T_{(R,\mathbf{t})}(\mathbf{x}) = R \mathbf{x} + \mathbf{t}$. Proof of this equation will be left as an exercise.
Rigid movement¶
Rigid transformations are used to represent movement of rigid bodies in space. If, in 2D the origin of a body moves by translation $\mathbf{t}$ in its original reference frame and rotates by angle $R = R(\theta)$, then the transformation that converts positional coordinates from the new coordinate frame to the original coordinate frame is given by $T_p(\mathbf{x}) = R \mathbf{x} + \mathbf{t}$. In other words, if $\mathbf{x}$ gives the coordinates of a position $P$ that is attached to the body, then after moving, $P$ will have coordinates $T_p(\mathbf{x})$ relative to the original body's frame. However, the transformation of directional coordinates will simply be a rotation and ignore translation: $T_d(\mathbf{v}) = R \mathbf{v}$. In other words, if $\mathbf{v}$ gives the coordinates of a directional quantity $V$ that is attached to the body (such as the direction of a line attached to the body), then $V$ will have coordinates $T_d(\mathbf{v})$ relative to the original coordinate frame (as in other directional quantities, these are interpreted ignoring the origin).
Representation of coordinate frames and coordinate transforms¶
Coordinate frames, as well as conversions between them, are interpreted as rigid transformations.
Any 2D coordinate frame $F$ with origin $O$ and axes $X$ and $Y$ may be represented by the coordinates of $O$, $X$, and $Y$ in some privileged world frame. If $O$ has coordinates $\mathbf{t}$, and $X$ and $Y$ have (directional) coordinates $\mathbf{x} = (x_{1},x_{2})$ and $\mathbf{y} = (y_{1},y_{2})$ relative to $W$, then the world coordinates of any point $P$ such that $\mathbf{p}$ is its coordinates in the frame $F$ can be calculated by the rigid transform
$$ \mathbf{p}_W = \begin{bmatrix}x_{1} & y_{1} \\ x_{2} & y_{2} \end{bmatrix} \mathbf{p} + \mathbf{t}. $$Hence, by storing $R = \begin{bmatrix}x_{1} & y_{1} \\ x_{2} & y_{2} \end{bmatrix}$ and $\mathbf{t}$ we can perform this calculation for any point in $F$. (We remark that the matrix is a rotation because $X$ and $Y$ are both orthogonal and $Y$ is $90^\circ$ ccw from $X$.) The information stored for a 3D coordinate frame is similarly a rotation matrix $R$ and origin coordinates $\mathbf{t}$. This operation is known as the coordinate transform $A \rightarrow W$ with $A$ the source frame and $W$ the target frame . We can also perform the reverse coordinate transform from $W \rightarrow A$ by applying the inverse transform.
Changes of coordinate frames can also be represented in terms of rigid transforms. Suppose $A$ and $B$ are two coordinate frames, where $A$ is represented with respect to the world frame by a rotation matrix $R_A$ and translation $\mathbf{t}_A$, and $B$ is represented by $R_B$ and $\mathbf{t}_B$. Then given the coordinates $\mathbf{p}^A$ of some point $P$ relative to $A$, we can determine $P$'s coordinates relative to $\mathbf{p}^B$ in two steps. First, we calculate its world coordinates:
$$\mathbf{p}^W = T_A(\mathbf{p}^A) = R_A \mathbf{p}^A + \mathbf{t}_A$$And then we perform the inverse of $B$ coordinates to world coordinate to obtain its coordinates with respect to $B$:
$$\mathbf{p}^B = T_B^{-1}(\mathbf{p}^W) = R_B^T (\mathbf{p}^W - \mathbf{t}_B).$$This transform can be calculated for all points by the composition of the transform from $A \rightarrow W$ and then $W \rightarrow B$: $$\mathbf{p}^B = T_B^{-1}(T_A(\mathbf{p}^A)) = R_B^T R_A \mathbf{p}^A + R_B^T(\mathbf{t}_A - \mathbf{t}_B).$$
Homogeneous coordinate representations¶
Homogeneous coordinates gives a convenient representation of rigid transforms as linear transforms on an expanded space. Moreover, it compactly represents the distinction between positional and directional quantities. The idea is to augment every point with an additional homogeneous coordinate, which is 1 if it is positional and 0 if it is directional. This operation is denoted with the hat operator $\hat{\cdot}$.
For 2D points and directions, we have $$\hat{\mathbf{p}} = \begin{bmatrix} p_x \\ p_y \\ 1 \end{bmatrix}$$ $$\hat{\mathbf{v}} = \begin{bmatrix} v_x \\ v_y \\ 0 \end{bmatrix}$$ Then, a 2D rigid transformation of both positions and directions is represented uniformly by a $3\times 3$ matrix multiplication: $$\hat{T}(\hat {\mathbf{x}}) = \begin{bmatrix} \cos \theta & -\sin \theta & t_x \\ \sin \theta & \cos \theta & t_y \\ 0 & 0 & 1 \end{bmatrix} \hat{\mathbf{x}}$$ where the original transformation $T(\mathbf{x}) = R(\theta) \mathbf{x} + \mathbf{t}$ is a rotation about angle $\theta$ followed by a translation of vector $\mathbf{t} = (t_x,t_y)$.
In 3D, the hat operator adds a 4th coordinate: For 2D points and directions, we have $$\hat{\mathbf{p}} = \begin{bmatrix} p_x \\ p_y \\ p_z \\ 1 \end{bmatrix}$$ $$\hat{\mathbf{v}} = \begin{bmatrix} v_x \\ v_y \\ v_z \\ 0 \end{bmatrix}$$ and a 3D transform is represented by a $4\times 4$ matrix multiplication: $$\hat{T}(\hat {\mathbf{x}}) = \begin{bmatrix} & & & t_x \\ & R & & t_y \\ & & & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix} \hat{\mathbf{x}}$$
Note that when applied to homogeneous positions, the rigid transform is applied to the first two coordinates of the vector while the homogeneous coordinate remains 1 (since the dot product of a position representation with the last row of the matrix is 1). Also, when applied to homogenous directions, only the rotation is applied to the first two coordinates of the vector, since the third 0 coordinate nullifies the effect of the third column. The homoeneous coordinate remains 0, since the dot product of a position representation with the last row of the matrix is 0.
The nice thing about this representation is that transform application is a matrix-vector multiply, transform composition is a matrix-matrix multiply, and transform inversion is a matrix inversion. This makes it much easier to write out complex transformations. For example, consider the problem of the coordinate transform from frame $A$ to frame $B$ that we described above. Rather than writing out the operator expression $T_B^{-1}(T_A(\mathbf{p}^A))$, using homogeneous coordinates this becomes a series of matrix-matrix and matrix-vector multiplies:
$$\hat{p}^B = \hat{T}_B^{-1} \cdot \hat{T}_A \cdot \hat{p}^A$$.
Working with coordinate representations of positions and directional quantities¶
In small 2D examples we can often treat coordinates casually, with our minds quickly filling in the gaps of meaning. However, once we introduce rotations, or move to 3D and beyond, this type of casual thinking runs the risk of making the robot walk through a wall! It is unlikely that your linear algebra software package (e.g., Matlab, or Numpy in Python) will help you guard against performing invalid operations, since you will be working with vector or matrix datatypes. Nor will they tell you how to properly convert between reference coordinate systems.
This section will once again discuss the importance of separating the coordinate representation of an object from its physical meaning. It will also describe some common pitfalls when working with coordinates, and tools to help reduce the risk of making calculation errors.
An illustrative example¶
Let us start with a running example where a point $P$ is drawn on a sheet of graph paper $G$. Some physical position is taken as the origin $O$ by convention, as are the axes $X$ and $Y$ which are attached to the graph paper. If we were to draw the straight line from $O$ to $P$, suppose the movement of the pen moves $p_x$ units in the $X$ direction and $p_y$ units in the $Y$ direction. If we were to move the paper (say, a few inches to the left and rotated 25$^\circ$), those dots have all moved in physical space, but since they were attached to the paper, the distances between them did not change. Nor did the 90$^\circ$ angle between $X$ and $Y$, nor did the distances from $P$ to the closest positions on the $X$ or $Y$ axes. Hence there are many physical quantities that have not changed, even through the positions themselves have.
Let us also suppose that just before moving the paper, we have erased the arrow, and now we need to draw it again. If we recorded precisely how our arm moved between $O$ and $P$ when the line was originally drawn, we can simply reproduce that arm movement (you know... like a robot) to draw $P$ again. We can see $O$ at the crossing of the axes, so we would simply need to find the new physical location of position $P$ to end the arrow. Luckily, we can still use the values $(p_x,p_y)$ to find $P$ given $O$, $X$, and $Y$. The procedure is simple: start at $O$, then walk $p_x$ squares in the new $X$ direction, and finally walk $p_y$ squares in the new $Y$ direction. Hence, we say that $(p_x,p_y)$ are the coordinates of the position $P$, relative to origin $O$ and axes $X$ and $Y$.
More formally, the coordinate frame defined by the physical position $O$ and directions $X$ and $Y$ defines a one-to-one correspondence between every point $P$ on the paper and the vector of coordinates $(p_x,p_y) \in \mathbb{R}^2$. It would also be desirable to be able to say that $P = O + p_x X + p_y Y$, as this corresponds with our casual understanding of how to "arrive at" $P$. However, we have only defined addition and scalar multiplication of vectors, not positions or directions (remember, $O$, $P$, $X$, and $Y$ are not themselves vectors, they are elements of thought with a physical meaning).
Luckily, we can do this more formally if we define $O$, $X$, and $Y$ with reference so some other privileged coordinate frame, which we will call the world frame $W$. If we let $\mathbf{p}^W$, $\mathbf{o}^W$, $\mathbf{x}^W$, and $\mathbf{y}^W$ be the coordinates of $P$, $O$, $X$, and $Y$ with respect to $W$, then we indeed have the relationship between their coordinates $\mathbf{p}^W = \mathbf{o}^W + p_x \mathbf{x}^W + p_y \mathbf{y}^W$. Moreover, $\mathbf{x}^W \cdot (\mathbf{p}^W - \mathbf{o}^W) = p^x$, and $\mathbf{y}^W \cdot (\mathbf{p}^W - \mathbf{o}^W) = p^y$. An important fact is that these equations hold regardless of the choice of world frame. Hence we can conclude that it is reasonable to casually state that $P = O + p_x X + p_y Y$, $X \cdot (P - O) = p_x$, and $Y \cdot (P - O) = p_y$ without regards to choosing a particular value of $W$.
Directional quantities¶
Next, let us illustrate how the coordinates of directional quantities transform. As an illustration, let us go back in time and add a second point $Q$ on the paper, and consider the line segment $\overline{PQ}$. Originally, $\overline{PQ}$ was drawn by moving a pen in a straight line from $P$ to $Q$, with a diplacement $D$. In the frame of the grid, this stroke moved the pen $d_x$ cells in the $X$ direction and $d_y$ cells in the $Y$ direction, with $(d_x,d_y) = (q_x-p_x, q_y-p_y)$.
Once the graph paper has moved, and we wish to draw $\overline{PQ}$ again in the paper's new location, but suppose that now instead of remembering $(q_x, q_y)$ we only remembered the values of $(d_x,d_y)$. To reproduce the movement starting at $P$, the stroke in the new displacement $D$ consists of a movement of $d_x$ units in the new $X$ direction and $d_y$ units in the new $Y$ direction.
Notice that the origin has dropped when performing this exercise, because the choice of origin when defining $(p_x,p_y)$ and $(q_x,q_y)$ cancels out when performing the difference. Using the same world coordinates trick as performed above, we can also say in casual shorthand that $D = d_x X + d_y Y$, $D = Q - P$, $d_x = D \cdot X$, and $d_y = D \cdot Y$.
Associating physical meaning to operations on coordinates¶
The main distinction between positions and directions is that the choice of origin does not affect how directions are represented. However, both are affected by the choice of coordinate axes. Hence, when performing changes of coordinates, the interpretation of position quantities changes in a different manner from that of directional quantities.
Positions and directional quantities also transform into each other when various operations are performed on them. When two positions are differenced, a displacement is produced. When a displacement is added to a position, another position is obtained. Displacements can be added to other displacements, or multiplied a scalar. However, it is meaningless to multiply a position by a scalar, or to add two position together, even though these are valid vector operations on their representations. (In cases where these latter two operations would seem to make sense, it is more appropriate to talk about displacements with respect to some other position.) Directions transform in much the same way that displacements do, but they do not scale or add.
In summary, the following mathematical operations on coordinates correspond to meaningful physical operations. The output of these operations (the right hand sides of the equations) may transform the type of object being represented. Here, P indicates a position, D indicates a displacement, V indicates a direction, and c is a scalar.
| Valid operations | Meaning |
|---|---|
| P - P = D | Calculating the displacement between points |
| P + D = P | Displacing a point by a displacement |
| D + D = D | Calculating the displacement caused by two displacements |
| c D = D | Scaling a displacement |
| D/‖D‖ = V if D ≠ 0 | Finding the direction of a displacement |
| c V = D | Scaling a direction to obtain a displacement |
Here, it is assumed that all items share the same coordinate frame. Operations on items not sharing the same coordinate frame are not meaningful, nor are the following types of operations:
| Invalid operations | Meaning |
|---|---|
| c P | Scaling a point |
| P + P | Adding two points |
| V + V | Adding two directions |
| P + V | Adding a direction to a point |
Finally, dot products and norms are meaningful only when performed on directional quantities.
Working with coordinates¶
When working with different coordinate representations, it is easy to make mistakes in calculations. Below are some common pitfalls.
Mistaken coordinate conventions include:
Assuming coordinates are given in a different frame.
Incorrectly assuming a matrix represents its inverse.
Incorrectly assuming a matrix represents its transpose (row-major vs column-major).
Assuming a coordinate frame is represented with respect to an incorrect base frame.
Applying a coordinate transform to a quantity not represented with respect to the source frame.
Operating on the wrong units (e.g., a frame's translation is expressed in m while the point's coordinates are expressed in mm)
To guard against these mistakes, it is common practice to indicate frames of reference with letters and annotate variables with their frame of reference. The superscript/subscript convention used by this book is popular amongst many authors. In this convention, we indicate the frame of reference of each coordinate variable in its superscript, e.g. $\mathbf{p}^A$ denotes a point expressed in frame $A$. A coordinate transform from frame $A$ to frame $B$ is expressed in the form $T_A^B$. Think about it this way:
$F$ in superscript: Coordinates should be interpreted as "relative to $F$".
$F$ in subscript: Coordinates should be interpreted as "describing the transform of frame $F$".
In this convention, superscripts and subscripts must cancel out for the equation to make sense. Specifically, the following rules apply:
When applying a transform to a coordinate, the subscript of the transform's source frame must match the point's superscript (reference frame). For example, $\mathbf{p}^B = T_A^B\mathbf{p}^A$ is allowed but $T_B^A \mathbf{p}_B$ is illegal.
When composing two transforms, the source frame of the second frame must match the destination of the first frame. For example, $T_A^C = T_B^C T_A^B$ is allowed but $T_A^B T_B^C$ is illegal.
When inverting a transform, the order of frames swaps: e.g. $(T_A^B)^{-1} = T_B^A$.
When adding or subtracting coordinates, their superscripts must match! For example, $\mathbf{a}^W - \mathbf{b}^W$ is the displacement between two points expressed in the world frame, but $\mathbf{a}^W - \mathbf{b}^C$ is an illegal operation.
By convention, a coordinate without a superscript is assumed to be associated with the world frame $W$: $\mathbf{p} \equiv \mathbf{p}^W$. Moreover,a coordinate transform $T_A$ is equivalent to a transform from $A$ to $W$: $T_A \equiv T_A^W$.
Matrix expressions are similar to standard expressions regarding real numbers in that addition and subtraction are equivalent, multiplication is nearly equivalent, and inverses give an approximation of division. But, this similarity leads to common pitfalls when manipulating matrix equations. Here are some common mistakes that should be safeguarded against:
Performing transformations out of order, or swapping the arguments of a matrix product (products are not commutative).
Propagating transposes or inverses into a matrix product without swapping the order of arguments.
Assuming that a matrix is invertible (or worse, assuming a non-square matrix is invertible).
Performing operations on matrices of incompatible size.
Coordinate management¶
It is essential when working with coordinates to understand 1) which coordinate frame is being used, 2) what unit is being used for measurement, and 3) do the coordinates represent a position or directional quantity? Failure to do so is a frequent source of errors. When we begin discussing forward kinematics, this requires substantial bookkeeping and notation. Moreover, in a production robot, dozens or hundreds of coordinate conventions may be used.
As a result, some middleware systems come with coordinate management
systems. These systems attach an annotation to a coordinate, so that
each position or directional quantity consists of a vector $\mathbf{p}$
stored alongside its annotation $A_p$. The annotation may include
whether the quantity is positional or directional, as well as an
identifier of its coordinate frame. The system will also store a
list of coordinate frames, represented in coordinates relative to some
privileged frame (usually called the "world frame"). Such systems will
allow users to query the coordinates of points and directions in
arbitrary frames, and to calculate coordinate transformation matrices.
With these systems, it becomes somewhat more convenient to maintain and
manipulate a large number of quantities and reference frames. Examples
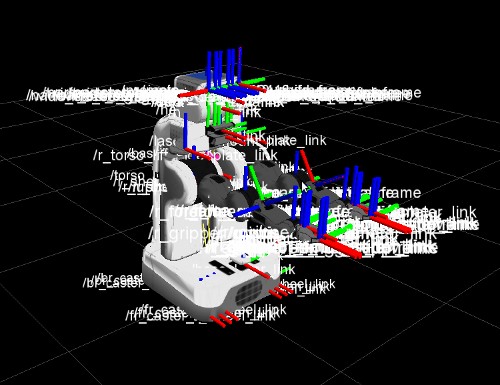
include the tf module in ROS
(Fig. 9) and the coordinates module in Klamp't.
The convenience of coordinate management systems comes at the cost of typically more verbose code and the learning curve of becoming familiar with a new API.
Summary¶
Key takeaways:
Coordinates are numerical representations of geometric concepts, like points, directions, frames of reference, and movement.
Points, directions, and displacements in $n$-dimensional space are represented by $n$-dimensional vectors, while rotations and scalings are represented by $n\times n$ matrices.
Rigid transformations consist of a rotation followed by a translation. They represent both rigid body movement and changes of coordinate frame.
Homogeneous coordinates represent rigid transforms using matrix multiplication in an $n+1$ dimensional space where the last coordinate is either 0 or 1.
When working with coordinates it is easy to make mistakes. Having clear assumptions, clear notation and/or using coordinate management software can reduce the risk of error.
Exercises¶
- Calculate the matrices representing $+90^\circ$, $+180^\circ$, and $-90^\circ$ 2D rotations.
Prove that $R(\theta)^{-1} = R(-\theta)$ using linear algebra and geometric identities.
Prove that $R(\theta_1) R(\theta_2) = R(\theta_1 + \theta_2)$ using geometric identities.
Give examples of 3D rotation matrices for which $R_1 R_2 \neq R_2 R_1$.
Prove that vector length is preserved under rotation $\| R(\theta) \mathbf{x} \| = \| \mathbf{x} \|$. Use this fact to prove that distance is preserved under rigid transforms.
Prove that all length-preserving transforms in 2D are either rotations or rotations followed by a mirroring transform:
$$ T(\mathbf{x}) = \begin{bmatrix} -1 & 0 \\ 0 & 1 \end{bmatrix} \mathbf{x}. $$
Produce the transform (i.e., rotation matrix $R$ and translation $\mathbf{t}$) that rotates any point $\mathbf{x}$ by $45^\circ$ about the point $(1,0)$.
What is the general form of a rotation of angle $\theta$ about a center point $\mathbf{c}$?
A mobile robot has a coordinate convention that $X$ is forward and $Y$ is to the left. It has an sweeping laser sensor attached to it that returns distance readings at all angles around the robot using a spinning mirror. The laser sensor gives perfect depth readings, and is attached so that the mirror's axis of rotation is centered at the point $(0.7,0.05)$ in the robot's $X,Y$ frame and oriented so that the $0^\circ$ reading is pointing in the robot's $X$ direction. At time $t$, the laser detects an obstacle at 1 m distance at the $15^\circ$ reading. At time $t+1$, the robot moves 0.5 m forward, 0.1 m to the left, and 20$^\circ$ counter-clockwise. Assuming the obstacle does not move, at which angle will the sensor detect the obstacle, and at what distance reading?
Suppose a 3D camera produces points $(x,y,z)$ in a coordinate frame that has $+x$ pointing to the right of the image, $+y$ pointing upward, and $+z$ pointing forward. Is the camera given with a right-handed or a left handed coordinate system?
Suppose we wish to find the transformation for points detected by the camera so that that the camera origin is placed at the coordinates $(1,0,2)$ in the world frame, its forward direction points in the world's $X$ direction, up in the image points in the $Z$ direction, and left in the image points in the $Y$ direction. Give a transformation for converting camera points to world points.
Prove ($\ref{eq:RigidTransformInverse}$), i.e., that $T_{(R,\mathbf{t})} ^{-1} = T_{(R^T,-R^T \mathbf{t})}$.
The midpoint between positions $P$ and $Q$ is given by the equation $M = 0.5 * (P+Q)$. But this expression appears to violate the assumptions above, stating that addition and scalar multiplication with positions are not meaningful operations. How can one make sense of this equation in terms of purely meaningful operations?
Implement a 2D coordinate management system, in your programming language of choice, where each position must be annotated with a frame. Your system should define an API to create positions and frames, and to retrieve coordinates of any position in any given frame. Frames should be identified with string names. The manager should maintain a list of named coordinate frames, each of which is represented in its coordinates relative to the world coordinate system (call this special frame "world"). Define a
Pointdata structure that stores two elementscoords: the point's coordinates, expressed in terms of its reference frame.frame: the name of its reference frame.
Do the same for a
Directionaldata structure. Now, implement methodsPoint.to(frame)andDirectional.to(frame)that compute a newPointandDirectional, respectively, whose reference frames are now the given frame, and whose coordinates are expressed correctly relative to the new frame.Extend the coordinate management system of exercise 12 to implement geometric operations, enforcing that each of the items needs to be of the same reference frame. Ensure that
Point - Point = Directional,Point + Directional = Directional,Directional +/- Directional = Directional, andDirectional * scalar = Directional.This tutorial for operator overriding in Python will come in handy here.
Extend the coordinate management system of exercise 12 to also include units that should be specified to the
Point,Directional, andFramestructure upon construction. Implement support for'm','mm','cm'and'km'arguments indicating meters, millimeters, centimeters, and kilometers.
#Skeleton code for exercise 12
class Frame:
#TODO: what here?
pass
#a dictionary from strings to Frame objects, to be used in Point.to and Direction.to
named_frames = dict()
class Point:
def __init__(self,coords,frame):
self.coords = coords
self.frame = frame
def to(self,newframe):
"""Returns a Point expressing the same physical point in space, but represented in the new frame"""
#TODO: what here?
return Point(self.coords,newframe)
class Directional:
def __init__(self,coords,frame):
self.coords = coords
self.frame = frame
def to(self,newframe):
"""Returns a Directional expressing the same physical direction in space, but represented in the new frame"""
#what here?
return Point(self.coords,newframe)